HyFromer笔记
推广搜
HyFromer
模型
将长序列信号与高维非序列信息进行整合已成为大规模推荐和搜索系统的核心挑战。HyFormer在单个骨干网络中统一了序列建模和特征交互。
这里需要解释一下概念
- 超长历史行为序列 (Ultra-long Historical Behavior Sequences) / 长序列信号 (Long Sequence Signals)
它指的是用户在平台上过去一段时间内,按照时间先后顺序发生的一系列交互行为。以前的推荐模型只能处理几十个最近的行为(短序列),而现在的工业级模型(如论文中提到的抖音搜索场景)为了更精准地捕捉用户的长期兴趣变化,会把序列拉得非常长,可能会包含用户过去几个月甚至几年的、多达几千个交互记录。
假设你正在刷抖音,系统需要预测你是否会点击下一个“科技测评”视频。 你的超长历史行为序列可能是你过去半年看过的 3000 个视频的记录:
[2025-12-01: 观看“数码相机推荐” (完播)] -> [2025-12-15: 点赞“显卡天梯图”] -> ... -> [2026-06-18: 滑走“游戏教程”]这个序列是有严格先后顺序的。 - 非序列稠密特征 (Non-sequential Dense Features) / 高维非序列信息 (High-dimensional Non-sequential Information) 它们代表的是当前的静态状态或上下文环境。 “稠密/高维”是相对“稀疏”而言的。用户的 ID 是极其稀疏的,但经过深度学习模型处理后(或者本身就是数值),会变成由一长串连续实数组成的向量(Embeddings),这就是“高维”和“稠密”的由来。它们包含了极其丰富的信息细节。 你的年龄、性别、手机型号、所在城市等
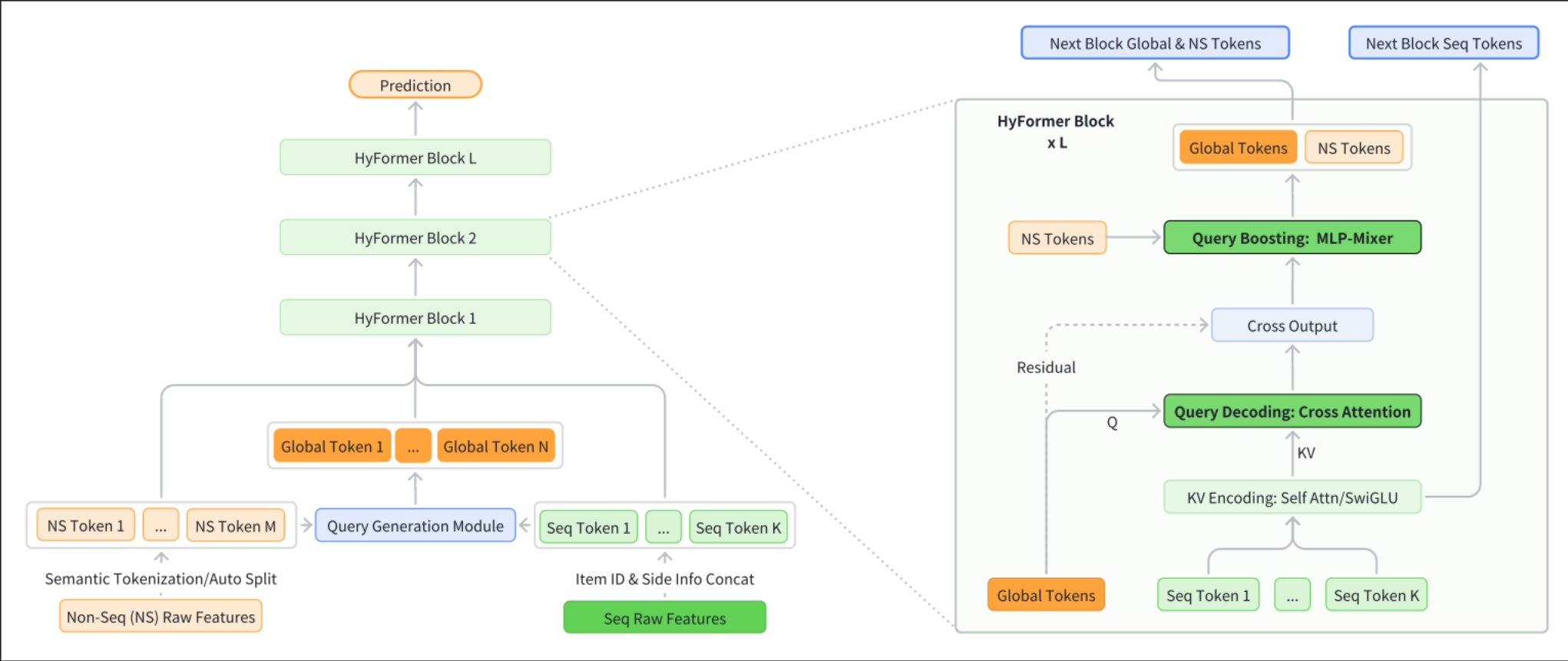
传统做法通常是让长序列自己进行编码(比如 Self-Attention 或 Pooling)得出一个浓缩特征。 但在 HyFormer 中,非序列特征(NS Tokens,比如用户年龄、设备类型、上下文等)在最开始就介入了。系统将 NS Tokens 与长序列的初步池化信息一起送入 Query Generation Module,生成了一组 Global Tokens。
在HyFormer Block 内部,长序列的特征(Seq Token 1…K)经过 KV Encoding 变成了 Key (K) 和 Value (V)。 此时,我们刚才生成的 Global Tokens 充当 Query (Q),与长序列的 KV 执行 Cross Attention。
这不再是漫无目的的序列压缩,而是非序列特征对长序列的query哪些细节对此刻最重要?输出的
Cross Output此时已经是一份带着上下文语义的序列表达了
拿到了带有序列信息的 Cross Output 还需要让它与原始的非序列特征做更深层次的交互。Cross Output与NS Tokens一起被送入了Query Boosting模块。最后会得到两个输出,Next Block Global & NS Tokens是增强后的Global Tokens ,Next Block Seq Tokens是新的序列特征,两个一起作为下一个HyFormer Block 的输入。
多个 HyFormer Block 会堆叠起来,随着网络的加深,Global Tokens 会吸收越来越丰富的长短语义,当它进入下一层再次作为 Query 去执行 Cross Attention 时,就能发掘出更深层、更隐蔽的序列依赖关系。
这块其实和transformer的形式是一样的
问答
- 为什么在 Query Boosting 阶段特意选用 MLP-Mixer 而不是 Self-Attention?
- 在推荐系统的异构特征交叉任务中,标准的 Self-Attention 往往容易“水土不服”。作者在对比分析中明确指出,像 MTGR 或 OneTrans 这样依赖 Self-Attention 进行特征交互的模型,通常会导致 AUC的下降 。MLP-Mixer 这种强制在 Token 空间维度和通道维度进行交叉的方式,在处理离散、异构的稠密特征时,能产生更有效的信号。
- 工业级大规模推荐模型对推理延迟和算力成本(FLOPs)有严格限制。Self-Attention 的计算复杂度是呈平方级增长的(),这会严重拖慢交互模块的速度 。而 MLP-Mixer 通过对每个 Query Token 进行独立的前馈变换,能够在进行特定子空间细化的同时,保持线性计算复杂度 。这就保证了模型可以在算力预算内叠得更深。
- 为什么 HyFormer 在面对更长、更丰富的历史序列信息时,能吃得下并转化为更高的准确率?
- 在传统的“先序列、后交互”架构中, 长序列被压缩成极少数的 Token ,它根本不知道后面的非序列特征(比如用户当前的明确意图、时间、地点)是什么,输入更长、更丰富的序列信息时,这些新增的宝贵细节(比如序列里某个不起眼的作者ID)往往在第一步压缩时就被稀释掉、甚至被当成噪音过滤了。后期的特征交互层拿到的,已经是一个“严重失真”的残缺摘要,数据再丰富也无济于事
- HyFormer 去提取历史序列时,它的 Query 已经融合了当前上下文和用户静态画像。当历史序列的特征变丰富了,HyFormer 就能真正把它们利用起来。
多序列建模
在真实的工业推荐系统里,用户的行为从来不是单一的。比如,在抖音的场景下,用户不仅有Feed 流视频观看序列,还会产生主动搜索序列 。
以往的一些模型,比如MTGR 和 OneTrans,为了图省事,通常直接合并,把不同类型的序列在维度上强行对齐,然后拼接成一个单一的、超级长的序列流来进行联合建模 。这种做法要求不同的序列必须共享同一组全局 Token,论文在实验中发现,这种简单粗暴的合并会导致模型AUC下降 0.06% 。
HyFormer在每个 Block 内部对每个行为序列进行了独立处理
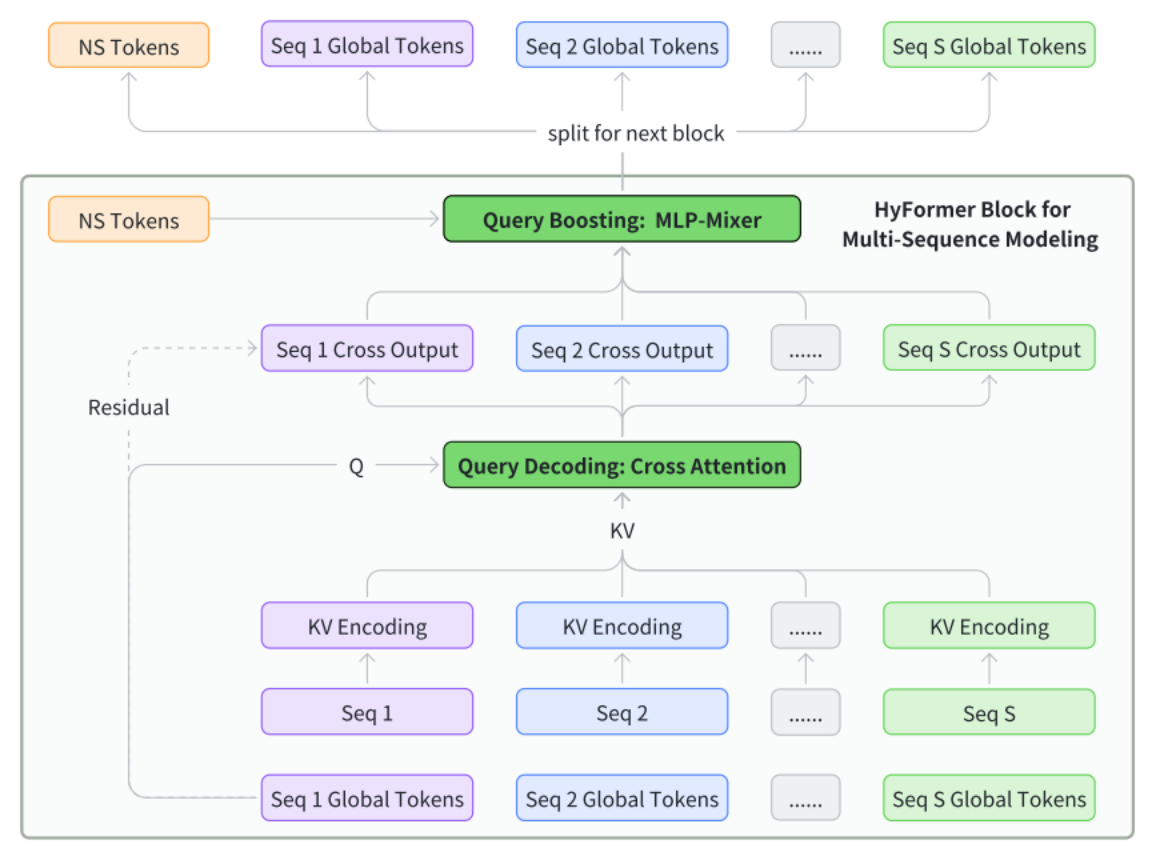
HyFormer 为每一种行为序列构建了专属的一组全局 Token 作为 Query 。在交叉注意力解码阶段,负责“搜索”的 Query 只去和搜索历史交互,负责“观看”的 Query 只去和观看历史交互。它们互不干扰,保留了各自序列特定的语义 。
当这些专属 Query 各自完成了对历史记录的提取后,它们会在紧接着的 Query Boosting 模块中汇聚 。在这里,不同序列提取出的深层次特征才开始进行深度的、Token 级别的跨序列交互 。
