Diffusion Policy笔记
embodied
diffusion
- 专家示范的正确动作具有高概率,也就是低能量
- 无效的、乱七八糟的动作则具有低概率,也就是高能量
- 纯随机的噪声,就相当于在这个能量场中处于非常高、非常边缘位置的毫无意义的动作 。
神经网络 并没有被训练去直接输出一个最终动作,而是被训练去预测当前数据里包含的噪声 (确信是ddpm)
流程
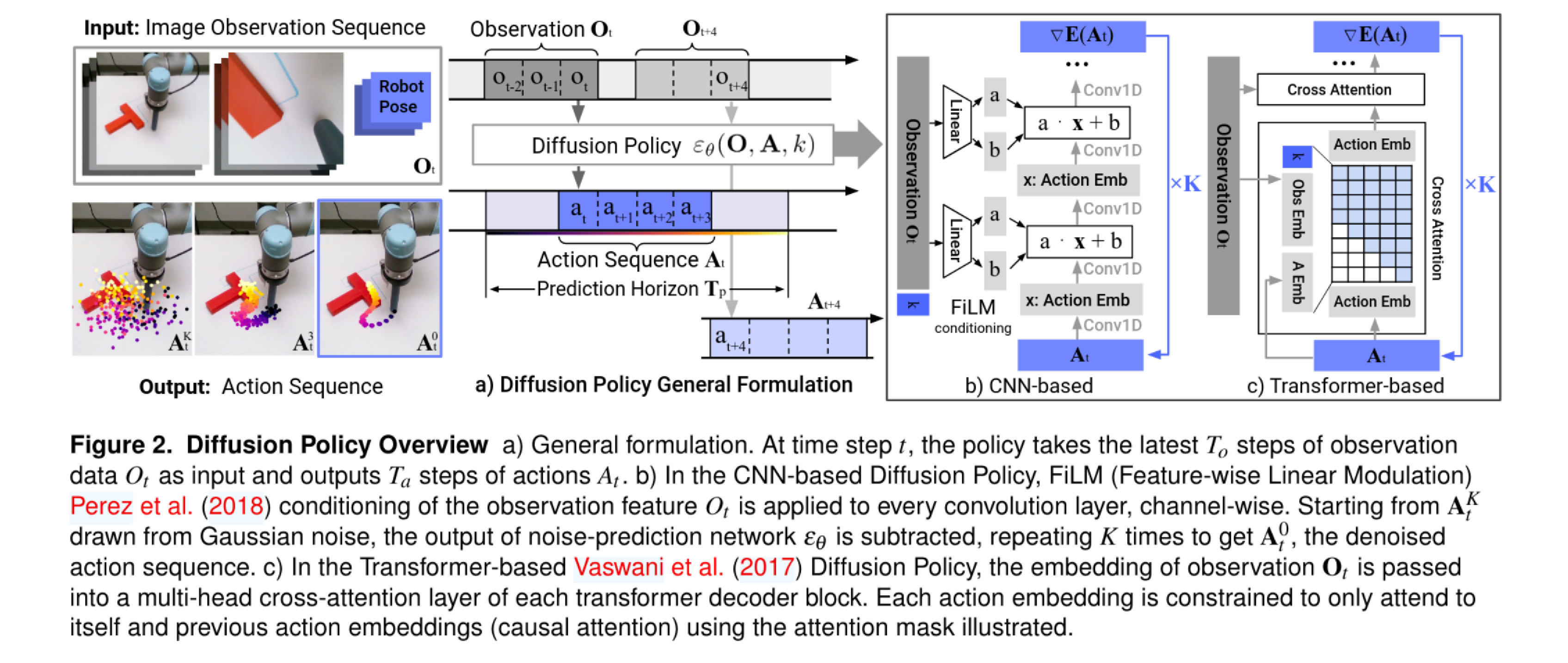
通过摄像头和自身传感器,获取过去 步的连续画面和机器人的本体状态 。
模型要预测未来 步的完整动作轨迹,先在多维动作空间中,凭空生成一段长度为 的纯高斯随机噪声序列,标记为 。此时他们是一堆毫无规律、漫天乱飞的动作指令
接下来循环去噪,系统一共要迭代 次 。在每一次迭代 中(倒计时从 到 1),神经网络 会同时接收三个关键输入:当前的噪声动作序列 、第 1 步获取的视觉观察特征 (作为引路的条件)、以及当前的去噪进度指示器 。通过ddpm的方式,模型将从当前的 中按一定比例减去噪声,从而得到稍微清晰、平滑一点的序列 。这个过程循环往复 次,初始的纯噪声就被一步步“雕刻”成了一条平滑、精准、且完美符合当前视觉场景的真实动作轨迹
虽然模型费尽千辛万苦规划出了未来 步的完美轨迹 ,但机器人并不会一股脑全部执行完 。为了应对物理世界可能发生的突发状况(比如目标突然被碰歪了),机器人只会执行这条轨迹中最前面的 步。然后重新获取最新的视觉画面,进入下一个循环的重新规划 。
其他
CNN 与 Transformer
论文对比了两种截然不同的架构 :
- CNN 架构: 论文使用一维时序卷积,并通过 FiLM 技术注入视觉特征 。它的优点是开箱即用,不需要太多调参,训练极其稳定 。但缺点是卷积网络容易产生过度平滑(Over-smoothing)效应,在处理需要剧烈速度变化的复杂任务时表现不佳
- Transformer 架构(挑战高难度): 针对 CNN 的缺点,作者将带噪声的动作序列作为 Token 输入 Transformer 解码器,并将视觉特征通过交叉注意力机制注入 。它在处理高频、极高复杂度的任务时表现出了最强的性能,但代价是对超参数(如丢弃率、权重衰减)非常敏感,训练难度更大
抗干扰
论文在真实的推 T 型块(Push-T)实验中,对机器人进行了严苛的干扰测试 :
- 视觉遮挡: 实验中途,人用手直接挡住前置摄像头长达 3 秒。虽然机械臂出现了轻微的抖动,但依然依靠之前的序列规划,精准完成了任务 。
- 物理抢夺: 在机器人即将完成动作时,人突然把 T 型块拨动到了另一个地方 。机器人没有死机,也没有继续对着空气推,而是立刻重新规划路径,甚至改变推的方向,把它弄回目标点 。
论文强调: 这种应对突然物理位移的纠错策略,在人类提供的示范数据中是从未出现过的。模型自己学会了根据画面变化合成新的行为 。
与真实世界的联系
作者通过数学推导证明,在一个简单的线性动力学系统中,如果仅仅让 Diffusion Policy 预测下一步(预测视野 ),它训练出来的去噪器,其行为在数学上会完美等价于经典的 LQR(线性二次型调节器)控制器 。
这意味着,Diffusion Policy 表面上是在模仿画面的动作,但其实它在隐式地学习物理世界的系统动力学规律 。
