act笔记
act
Action Chunking with Transformers
embodied ai
robotics
Action Chunking with Transformers
与传统策略一次只预测一个动作不同,ACT 会将动作打包,一次性预测未来 k 个时间步的动作序列 。这成倍地缩短了任务的有效预测跨度,从而有效缓解了误差累积问题 。
ALOHA 遥操作平台
超低成本,主要由市售的廉价机械臂(ViperX 和 WidowX)和 3D 打印部件组成 。
操作员通过直接拖动较小的“领导者”机械臂,让较大的“跟随者”机械臂同步运动 。这种方式能提供极高的控制带宽,并有效过滤轻微的震动,使操作更加直观稳定 。
ACT
传统的模仿学习策略是预测下一步的动作,即单步预测 。而在精细操作中,微小的单步误差会迅速累积导致任务失败 。 ACT 改变了这一做法,它在接收到当前观测结果后,会直接生成未来 个时间步的目标关节位置序列(即 ) 。
如果机器人每隔 步才观察一次环境并执行动作块,会导致运动非常生硬和卡顿 。为了提高动作的平滑度,ACT 在每一个时间步都会查询策略网络 。
这意味着不同时间步预测出的动作块会发生重叠 。
ACT 提出使用一种指数加权方案 (其中 是最旧动作的权重),对针对同一个未来时间步的多个预测动作进行加权平均 。这种集成方式不需要额外的训练成本,只需在推理时进行计算即可产生极其平滑和精确的动作 。
ACT 将策略训练为一个条件变分自编码器(CVAE) 。模型被分为 CVAE 编码器 和 CVAE 解码器(即实际的策略网络) 。通过引入一个风格变量Style Variable ,ACT 能够捕捉人类演示中的变异性 。
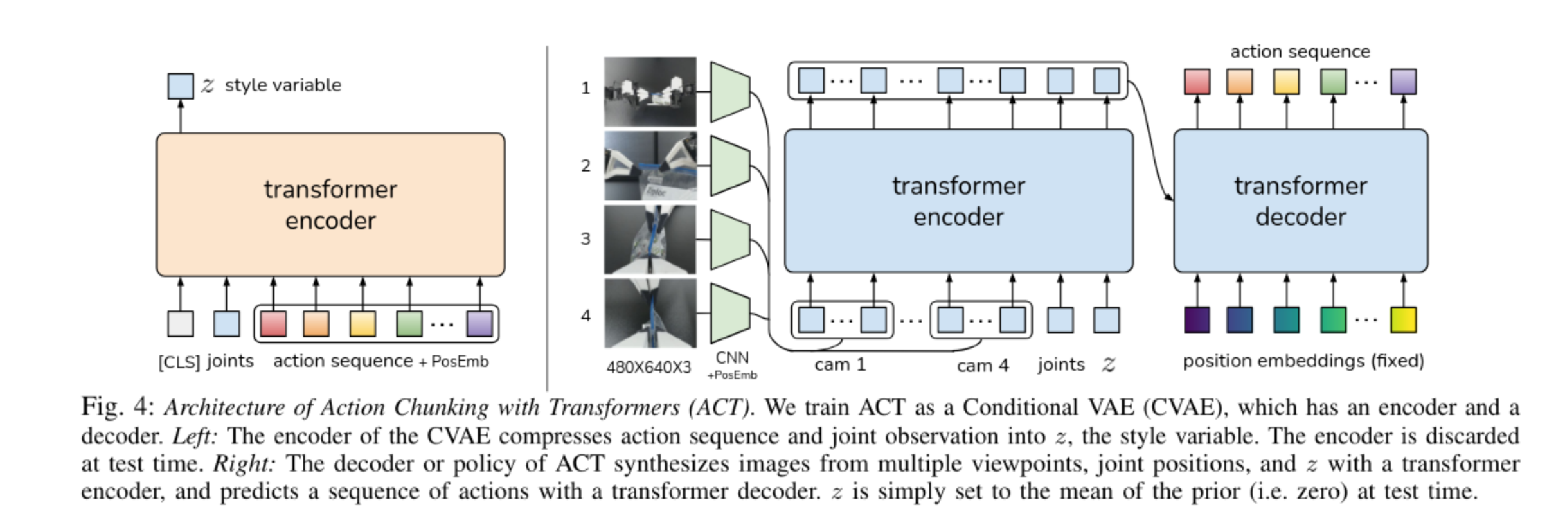
训练
CVAE 编码器(一个类似 BERT 的 Transformer 编码器)接收当前机器人的关节位置、演示数据中的目标动作序列 ,以及一个预设的 [CLS] token 。它将这些信息压缩,并通过 [CLS] token 输出的特征来预测风格变量 的均值和方差(参数化为对角高斯分布) 。
4 个摄像头的 RGB 图像分别通过 ResNet18 提取特征,展平后加入 2D 正弦位置编码以保留空间信息 。
图像特征序列与当前的关节位置、以及采样得到的风格变量 拼接在一起,送入 Transformer 编码器 。随后,Transformer 解码器利用交叉注意力机制结合固定的位置编码,输出一个 的张量,最后通过 MLP 降维成 的目标动作序列, 即未来 步中 14 个关节的目标位置。
使用标准的 VAE 目标函数进行优化,包含重构损失和约束 的 KL 散度正则化项 。
ACT 发现使用 L1 损失比 L2 损失能获得更精确的动作建模
推理
在实际部署时,CVAE 编码器会被直接丢弃。由于没有了真实的未来动作来推断风格变量 ,ACT 会直接将 设置为先验分布的均值也就是全零向量 。
CVAE 解码器(策略网络)仅根据当前摄像头画面、当前的关节位置以及这个设为 0 的 ,确定性地输出未来 步的动作块序列 。
