DDPM笔记
ddpm
diffusion
DDPM加噪声就是按照一个公式每一步添加一些噪声,当n趋向无穷这就是一个完全的的噪声了。去噪声就是反着来,但是因为我们不知道这个噪声,所以我们就可以用一个unet来预测这个噪声,然后还在unet里面加了个t embedding。为了表示真实的噪声和预测的噪声,就用l2 loss来表示两个噪声的差异。然后用加噪声的公式可以推一个去噪公式出来,然后采样一个噪声,进行去噪,这样就可以生成一副图像了
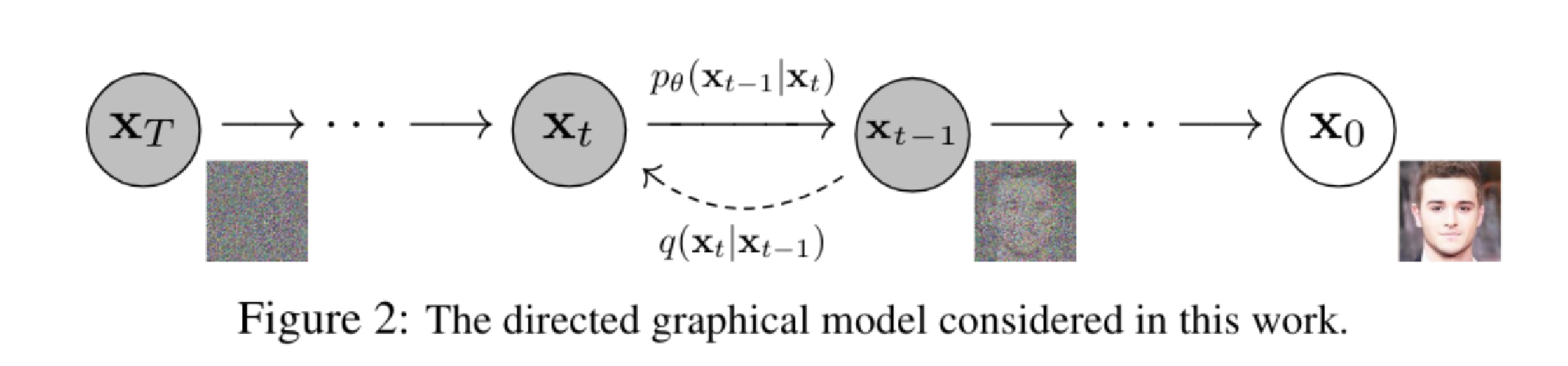
背景知识
文章开篇告诉我们, 是真实的清晰图像, 到 是加了不同程度噪声的中间的图像,因为从纯噪声变回清晰图像的路径有无数条,所以要算出生成特定清晰图像的总概率,必须把所有可能的中间路径全部积分(累加)起来。
生成过程(逆向过程)的起点 必须是一个标准的多元高斯分布
我们要做的,就是从一堆纯噪声 出发,一步步往回走,直到画出 。是整个生成轨迹的联合概率分布,它表示从纯噪声 开始,经过 、……一路走到清晰图像 的总概率。(公式1)
因为这是一个马尔可夫链,每一步只依赖上一步,所以总概率等于每一步概率的乘积。
首先是逆向过程是单步去噪操作,在已知当前稍微模糊一点的图像 的情况下,推测上一步更清晰一点的图像 长什么样。作者假设这每一步的推测也符合高斯分布。因为我们不知道真实的去噪分布是什么,所以要训练一个神经网络,让它根据当前的图 和时间步 ,来预测去噪后的均值 和方差 。( 和 :这里带了下标 ,代表神经网络的参数。)(公式1)
接下来是前向过程,拿一张清晰的图,每次往里面倒一点点噪声,倒 次之后,图就彻底看不清了。这个过程是固定的,没有参数需要学习
- 是给定清晰原图 的前提下,生成整条逐渐变糊的轨迹的概率。(字母 通常代表真实的数据分布或固定的后验分布,以区分前面代表模型的 )。
- 是单步加噪操作,在上一个时刻的图 的基础上,加上一点点噪声变成 。(公式2)
是一个极小的正数(比如 0.0001 到 0.02),代表这一步我要加多少比例的噪声进去。均值 代表每次加噪,原图的信息会乘上一个略小于 1 的系数(),这意味着原本的图像信号在轻微衰减。方差 是指注入方差为 的纯高斯噪声。(公式2)
前向传播一步到位
前向传播其实有一个捷径,就是下面的公式,可以直接从原图 一步跳跃计算出任意时刻 的噪声图 (可以理解成在已知原图是 的前提下,按照加噪规则,生成你手里 的概率有多大)(公式4)
这个形式有点突然,我们来推导一下
如果一个变量 ,那么我们可以把它写成:(重参数化技巧,相当于从一个标准正态分布中采样一个噪声变量,然后通过缩放和平移,计算出 )
如果有两个相互独立的正态分布变量 和 ,那么把它们加在一起,依然是一个正态分布,且方差直接相加:
我们知道第 步的加噪过程是(这里直接用了论文里提到的 的代换):
利用重参数化技巧,我们可以把 明确地写成等式:
既然 可以用 表示,那么 同理也可以用 表示:
现在,我们把这个 的表达式代入到第一步的 的公式中:
把括号展开:
仔细看公式后面那两项,它们都是服从正态分布的纯噪声乘以一个常数
- 第一坨噪声的方差是:
- 第二坨噪声的方差是:
这两个独立的噪声加在一起,等价于一个新的高斯噪声,它的方差是两者方差之和:
所以,这两坨噪声可以被完美融合成一坨新的标准噪声 :
当我们从 倒退到 时:
- 前面的系数变成了
- 噪声前面的系数变成了
如果我们顺着这个规律,像套娃一样一路代入 一直代入到最原始的清晰图片 :
- 前面的系数就会累乘所有的 ,也就是 。论文把这个累乘结果定义为 (即 ),所以系数就是 。
- 而后面那坨融合了无数次的噪声的方差,就会顺理成章地变成 ,也就是 。
最终的等式就变成了:
再用概率分布的语言重新写出来,就是这个公式了:
损失函数
既然是训练我们需要有一个损失函数(公式3)
整体上我们需要一个对数似然 (NLL),也就是说我们希望模型生成真实图片 的概率越大越好,也就是让负对数似然越小越好。
但是左边这玩意儿算不出来(需要对所有中间状态积分,计算量爆炸)。所以我们在数学上找了它的一个上限。只要我们把这个上限 优化得足够小,真实的负对数似然也会跟着变小。
等号最右侧的展开式是把上限拆开后的结果。它本质上是在度量模型预测的去噪路径 和 真实发生的加噪路径 之间的差异。
但是 里面包含了一个很难算的对数期望。作者利用贝叶斯公式和马尔可夫链的性质,把 巧妙地拆成了三项相加(原文公式 (5)):
- (最左边): 比较 前向过程最后一步生成的纯噪声 和 标准的正态分布噪声 。因为我们在前向过程设定的 是固定的常数(不参与梯度下降),所以这一项对于网络参数 来说是一个常数。在训练时,直接忽略它就行。
- (最右边): 这是最后一步的重构项,衡量模型从 恢复到最终毫无噪声的真实图片 的能力。
- **:
这部分在算一个 KL 散度,衡量两个分布的差异。
- 右边 :这是模型给出的去噪预测
- 左边 :这是真实发生的后验去噪分布,也就是在知道最终清晰原图 的上帝视角下,从 退回 的真实路径 也就是说训练目标让你的模型预测,尽可能去逼近那个真实路径。(这不是废话吗)
那这个真实的后验分布”,到底怎么算?我们单看 是算不出来的,如果我们加上了条件 ,也就是知道原图长啥样),这就变成了一个非常确定的贝叶斯概率问题
作者告诉我们,这个后验分布依然是一个优雅的高斯分布(原文公式 6):
原文公式 (7) 则给出了这个高斯分布的具体均值 和方差 的计算方法:
也就是说第 步的真实状态,其实就是 最终的清晰原图 和 当前的噪声图 两者之间的一个加权平均。其中 和 就是那些预先算好的衰减系数。
这解决了深度学习中一个巨大的痛点。本来,衡量两个复杂分布的差异是非常困难的,往往需要用到方差极大、极其不稳定的蒙特卡洛采样。但是,因为作者证明了 是高斯分布,而我们的模型 也设定为高斯分布,两个高斯分布之间的 KL 散度是有解析解的!
两个方差固定的高斯分布的 KL 散度,在数学上等价于直接计算它们均值之间的均方误差(MSE)。这就意味着,原本极其复杂的概率论损失函数,在代码实现时,直接退化成了非常基础的
Loss = MSE(真实的均值, AI预测的均值)
我们还是来说一下一下这个优雅的高斯分布,具体可以参考1
在已知最终原图 和当前噪声图 的情况下,求上一步 的概率分布,即 。
根据贝叶斯公式,我们可以把它展开:
接下来,利用马尔可夫链的性质(当前状态只跟上一步有关,所以 里的 是多余的,可以直接去掉),公式变成了这样:
我们可以观察到,右边这三项全是条件概率
- :这是单步加噪过程,根据公式 (2),它是一个高斯分布。
- :这是从原图直接跳跃到第 步的加噪过程,根据捷径公式 (4),它也是一个高斯分布。
- :这也是从原图直接跳跃的加噪过程,还是一个高斯分布。
三个高斯分布的公式乘除在一起时,就相当于把它们 里面的指数部分进行加减运算。接下来就是把这三坨二次多项式展开,把同类项合并,然后再重新配方,强行把它凑成一个新的 的形式
扩散模型
接下来作者通过一波巧妙的公式代换,向大家证明让 AI 预测高斯分布的均值,在数学上完全等价于让 AI 直接预测图片里被加进去的纯噪声
作者首先处理了公式 (5) 里那个最左边的项 ,在前向过程里加的噪声参数 是人为定死的常数,不参与深度学习的梯度回传。所以 这个衡量纯噪声差异的项,在训练过程中根本不会变,所以直接不算!
接下来看核心项 。前面说了,模型预测的去噪分布 是一个高斯分布,它有两个参数:均值 和方差 。作者决定不去让神经网络预测方差了! 他直接把方差 设定为了常数 , 模型的负担又减轻了一半,现在只需要专心预测均值 就可以了。
实验证明设为 或者上一节推导的 效果都不错
有原图 的真实后验分布是一个均值为 的高斯分布。因为两个方差固定的高斯分布的 KL 散度等价于均方误差,所以Loss 就是(公式 (8) ):
最直接的做法,就是让神经网络 直接去预测 。
作者没完了。他又利用前面公式 (4) 的重参数化技巧,反向解出 ,然后代入到推导出来的 公式里。经过一通代数化简,作者得到了一个极其震撼的结果。真实均值 被化简成了这样(公式 (10) ):
是最开始的噪声图片, :全都是提前设定好的常数, 是在第 步时,图片里包含的纯噪声
==也就是说,真实的均值完全可以由 当前图片 和 图片里的噪声 经过简单的加减乘除算出来,而 网络本来就知道,那不如直接让神经网络去预测图片里的那坨纯噪声 ==
既然真实均值 可以写成包含当前噪声图 和真实纯噪声 的形式
又要让要让神经网络预测均值,那我们就强制要求神经网络的输出格式,长得跟真实的均值公式一模一样。唯一的区别是:把里面那个未知的真实噪声 ,替换成神经网络自己猜的噪声 。于是,我们有公式 (11)
当神经网络推理出了噪点 后,只需要做简单的加减乘除,就能无损地把它翻译成去噪后的图像均值 。 这样,模型就变成了专门找噪声的工具。
我们把公式 (11) 代入到之前的损失函数(Loss)里。
之前的 Loss 是真实均值和预测均值的均方误差: 我们把上面两个长长的式子相减:
庞大且复杂的已知图像项 在相减时完美抵消了!剩下的项提取公因式,就只剩下了关于噪声的差值:
因为外面有一层平方 ,所以负号没了,前面的系数被平方后提到了最外面。最终的 Loss 瞬间坍缩成了公式 (12):
作者通过精妙的代数代换证明了:==均值的误差,在数学上绝对等于噪声的误差,只是前面多乘了一个常数系数而已==。
解码
还有一个问题,模型算到最后一步了,怎么把概率,变回图片?
首先在训练阶段,平时我们电脑里的图片,像素值都是 0 到 255 的整数。但如果我们直接拿 0~255 的数据去训练,会出大问题。因为扩散模型的终点是一个标准正态分布 (均值为0,方差为1)。如果你的图像像素值高达 255,那么方差为 1 的噪声加进去没有效果;反过来,如果要强行把 255 变成纯噪声,需要的方差会极大,导致模型极其不稳定。作者在数据预处理时,把所有 的像素,线性映射到 之间 。这样,真实数据和终点的标准高斯噪声就处于同一个数值量级了,神经网络处理起来非常舒服 。
推理时,像素值是离散的,但我们的神经网络输出的是一个高斯分布的均值 和方差 ,这是一个连续的概率密度函数。作者的解法是积分:对于第 个像素,如果真实的像素值是 ,作者就拿神经网络预测出的那个高斯分布,在 这个小区间里求积分
作者还处理了边界情况,这样的处理是因为高斯分布的尾巴是无限长的。如果模型预测像素值为 1,但它输出的高斯分布有一部分“溢出”到了 1.1、1.2 甚至 2.0 去,如果我们只积分到 1.0,这部分溢出的概率就白白丢失了,导致总概率加起来不到 100%。
作者通过把边界设为无穷大,所有预测超过 255 的概率,统统算作 255;所有预测低于 0 的概率,统统算作 0。这就保证了概率的不流失
在采样的最后一步(从 变回最终图片),绝对不能加噪声了! 只需要直接把网络预测出来的均值 拿出来,丢掉所有的抖动,映射回 0~255 显示在屏幕上即可 。
真正的损失函数
作者给出了简化后的损失函数
随机抽一张干净的原图 ,随机抽一个时间步 ,随机生成一坨纯噪声 ,拿真实的纯噪声减去AI预测的噪声,求均方误差
概括一下,随机给图片加任意程度的噪声,然后让网络去猜加进去的噪声长什么样。
对比前面的公式12,
作者把 MSE 前面那一大坨极其复杂的系数权重(由 和 组成)直接扔掉了, 变成了一个不带任何权重的纯 MSE 损失
作者指出,简化版损失函数生成出来的图片质量更好,因为在严格的公式 (12) 中,当 很小(加的噪声极少,图片很清晰)时,前面的权重系数会变得非常大 。这意味着如果用原版公式,神经网络会把大部分精力花在如何修复那些肉眼几乎看不见的微小细节上 。把权重扔掉后,相当于降低了小 (微小噪声)的惩罚权重 。这样一来,神经网络就被迫把更多的精力转移到那些 比较大(噪声很大、任务极其困难)的阶段 。
Footnotes
-
Sohl-Dickstein, Jascha, et al. “Deep Unsupervised Learning Using Nonequilibrium Thermodynamics.” arXiv.org, 12 Mar. 2015, https://arxiv.org/abs/1503.03585. ↩
